不知道为什么,m_ntmap会丢失,明明在Set阶段,m_ntmap的大小是不断上升的,而到了Create阶段,m_ntmap大小变为0。
而与其几乎相同实现方式的m_interfaceExclusions则不会有这个问题,有可能是Map的性质问题。其实是CopyConstructor忘记实现了。
之前遇到报错说,RoutingProtocol没有Constructor,其实要在SetTypeID时把constructor加进去。
不知道为什么,m_ntmap会丢失,明明在Set阶段,m_ntmap的大小是不断上升的,而到了Create阶段,m_ntmap大小变为0。
而与其几乎相同实现方式的m_interfaceExclusions则不会有这个问题,有可能是Map的性质问题。其实是CopyConstructor忘记实现了。
之前遇到报错说,RoutingProtocol没有Constructor,其实要在SetTypeID时把constructor加进去。
现在的问题是如何确定MainAddress。
发现NodeType也要事先确定。
现在NT通过Helper中的SetNodeTypeMap传递,并在Helper中的Create传递给RoutingProtocol.
21:49 已经将SDN.CC中的传递实现
SetMainAddress应该要根据NodeType执行,
ipv4routinghelper 在调用Create时,会传入Node,如果在调用ipv4routinghelper之前Node已经安装好mobility,路由算法可以在ipv4routinghelper中的Create时,取得其mobility,就不用另外实现一个输入mobility的过程。
一开始的想法是,SDN的指令信息运行在CCH,而数据信息则运行在SCH,那么这样路由协议就需要知道各个节点的“真实ID”。
HelloMessage内含ID,应该是车辆SCH的IP,而不是CCH的IP,因为RM下发时,是广播的,车辆只需要判定下发的RM中,ID是否和自己的SCH ip相同即可。
而由于LC理应只工作在CCH,所以只有CCH ip,LC的ID就是他的IP。
Thresholding
Origin:
Basic Global Thresholding:
Mean:
Median:
Optimum Global Thresholding Using Otsu’s Method:
Kapur:
Kittler–Illingworth:
四图的顺序是原图,0.25椒盐噪声污染后图,7×7中值滤波,Smax=7自适应中值滤波。



效果太好
看到试一下而已
原图

灰度

直方图均衡
9×9中值滤波
9×9均值滤波

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
remote refid st t when poll reach delay offset jitter ============================================================================== +time-a.nist.gov .ACTS. 1 u 117 128 375 219.880 -3.162 9.807 +time-b.nist.gov .ACTS. 1 u 63 128 377 212.481 4.291 10.382 +time-c.nist.gov .ACTS. 1 u 72 128 373 221.437 -4.065 15.729 +time-d.nist.gov .ACTS. 1 u 123 128 377 224.083 -4.272 13.544 +24.56.178.140 .ACTS. 1 u 80 128 377 190.612 -7.805 4.921 x128.138.141.172 .ACTS. 1 u 114 128 377 316.636 48.359 8.748 +131.107.13.100 .ACTS. 1 u 251 128 376 164.240 -11.402 8.598 +223.255.185.2 .MRS. 1 u 855 128 100 12.286 5.916 11.465 +ntp-a2.nict.go. .NICT. 1 u 14 128 173 54.171 4.101 7.690 #ntp0.nc.u-tokyo .GPS. 1 u 500 128 370 115.024 -35.263 8.081 +ntp-sop.inria.f .GPS. 1 u 14 128 253 222.405 -2.242 23.575 +ntp-p1.obspm.fr .TS-3. 1 u 114 128 377 317.704 -1.992 14.829 *ts0.itsc.cuhk.e .GPS. 1 u 43 128 377 6.798 4.658 6.391 +ntp.ix.ru .PPS. 1 u 124 128 373 424.717 -9.539 10.470 +ntp.neu.edu.cn 95.222.122.210 2 u 8 128 377 52.216 1.041 5.245 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
remote refid st t when poll reach delay offset jitter ============================================================================== LOCAL(0) .LOCL. 10 l 46h 64 0 0.000 0.000 0.000 #time-a.nist.gov .ACTS. 1 u 15 256 377 378.818 -83.364 17.463 #time-b.nist.gov .ACTS. 1 u 70 256 277 476.310 -41.924 35.146 #time-c.nist.gov .ACTS. 1 u 7 256 377 395.963 -43.723 34.185 #time-d.nist.gov .ACTS. 1 u 12 256 377 483.643 -34.337 30.085 #24.56.178.140 .ACTS. 1 u 221 256 371 291.978 50.514 46.840 -131.107.13.100 .ACTS. 1 u 136 256 377 177.669 -6.028 139.785 *118.143.17.82 .MRS. 1 u 188 256 357 13.079 0.081 0.350 +ntp-b3.nict.go. .NICT. 1 u 142 256 377 63.631 -0.085 0.274 +ntp0.nc.u-tokyo .GPS. 1 u 161 256 377 63.430 -0.350 24.636 -ntp-sop.inria.f .GPS. 1 u 20 256 377 243.417 2.893 1.610 -ntp-p1.obspm.fr .TS-3. 1 u 113 256 377 302.075 -4.333 37.451 #ts0.itsc.cuhk.e .GPS. 1 u 151 256 365 75.393 32.617 54.784 -ntp.ix.ru .PPS. 1 u 211 256 377 414.779 5.133 9.858 -ntp.neu.edu.cn .PPS. 1 u 150 256 377 65.779 0.803 7.601 #ptbtime1.ptb.de .PTB. 1 u 63 256 377 354.657 20.788 16.343 -ptbtime2.ptb.de .PTB. 1 u 13 256 377 333.716 8.016 1.129 -ptbtime3.ptb.de .PTB. 1 u 59 256 377 348.999 1.459 19.869 |
用Scrapy及Gensim对哔哩哔哩弹幕网的标签进行Word2Vec语义分析
本来是课程作业, 但也还是放出来吧.
Scrapy是一个爬虫,Gensim则是一个语义分析软件。Word2Vec是一个“深度学习”的,将一个个单词变为一个个向量的算法。
实际操作过程很简单, Scrapy抓Bilibili, Gensim对结果做Word2Vec分析, 然后用Tkinter写UI界面.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import codecs import scrapy from b.items import CHL import re class MySpider(scrapy.Spider): name = 'bili' allowed_domains = ['www.bilibili.com'] amy = ['http://www.bilibili.com/'] for i in range(7,2878725): amy.append("http://www.bilibili.com/video/av"+str(i)) start_urls = amy def parse(self, response): item = CHL(); try: item['tag'] = response.xpath('//meta[@name=\'keywords\']/@content').extract()[0] thestr = item['tag'].replace(',',' ') + '\n' with codecs.open('2878725', 'a', 'utf-8') as f: f.write(thestr) except IndexError: pass return item |
因为前几天上Bili发现编号只到2878725,所以就到2878725了。作业的版本是用CrawlSpider的,但其实B站视频编号连续,顺序爬就可以。顺序爬的速度比用爬虫爬快好多,而且占用资源也少。之前爬虫爬到结果大概不足100M,Linode那VPS就已经内存不足了,现在完整结果有316M。
由于有很多投稿失效或者是”只有会员知道的世界”,爬完后的结果里面,会有很多B站的默认Tag.为避免影响结果,要删去.
|
1 |
grep -v 'B站 弹幕 字幕 AMV MAD MTV ANIME 动漫 动漫音乐 游戏 游戏解说 ACG galgame 动画 番组 新番 初音 洛天依 vocaloid' 2878725 > 2878725fl |
2878725fl大约比2878725小一半…….
下一步之前还要把2878725fl改个名叫input
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/env python # -*- coding: utf-8 -*- import gensim, logging, codecs class MySentences(object): def __init__(self, dirname): self.dirname = dirname def __iter__(self): for line in codecs.open(self.dirname, 'r', 'utf-8'): yield line.split() logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = MySentences('input') model = gensim.models.Word2Vec(sentences, size=400, workers=24, min_count=3) model.save('w2v') model.init_sims(replace=True) model.save('w2v.trim') |
由于init_sims能极大减少内存占用,但却会令模型不能继续训练,所以就开启前后分别保存了一份,以备不时之需。这里的Size取了400,400就是向量的维度。
8192维的耗时
|
1 |
training on 19973050 raw words took 1883.2s, 10036 trained words/s |
400维的耗时
|
1 |
training on 19973050 raw words took 153.5s, 123083 trained words/s |
到准备重现UI时,发现32位的Python吃不了那么大的数据(1024维),去搞64bit的,所有包都要重新装….
http://www.lfd.uci.edu/~gohlke/pythonlibs/
上面这个网址有编译好的windows包可以直接用
举个栗子,下载numpy, 先把
numpy-1.9.2+mkl-cp27-none-win_amd64.whl下下来
然后
|
1 2 3 4 5 6 7 |
C:\Users\CHL\Downloads>pip install "numpy-1.9.2+mkl-cp27-none-win_amd64.whl" Unpacking c:\users\chl\downloads\numpy-1.9.2+mkl-cp27-none-win_amd64.whl Installing collected packages: numpy Successfully installed numpy Cleaning up... C:\Users\CHL\Downloads> |
搞定,然后就Scipy和Gensim,同理。
今天中大东校区IPv6废了,网速直线下降(我一直挂着v6跑)
下面就是TheB跑出来的结果截图
相似查询概念很简单,就是找出向量距离近(相关度高)的结果
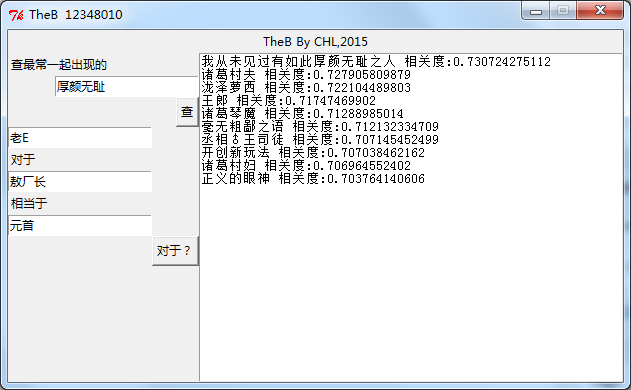
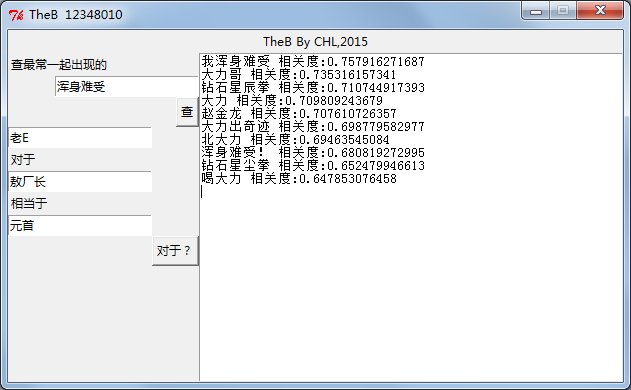
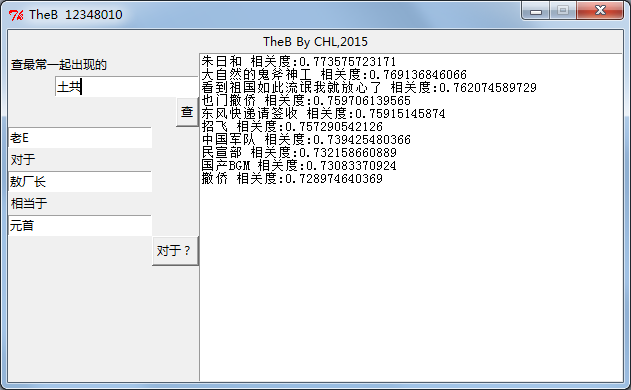
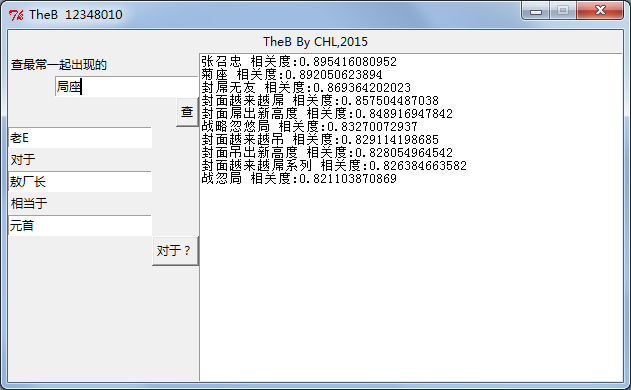
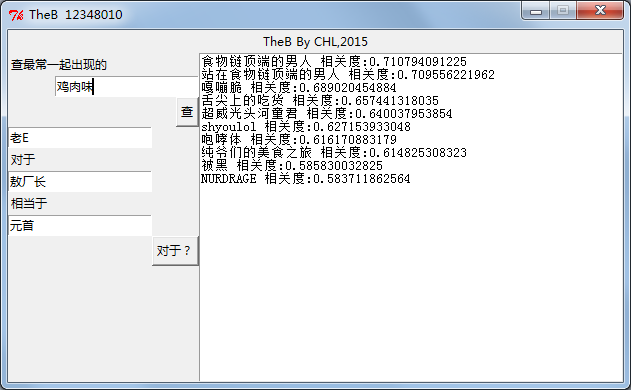
类比查询则比较有意思,一个简单的例子就是,queen对于girl相当于king对于boy。运算: boy=girl-queen+king。

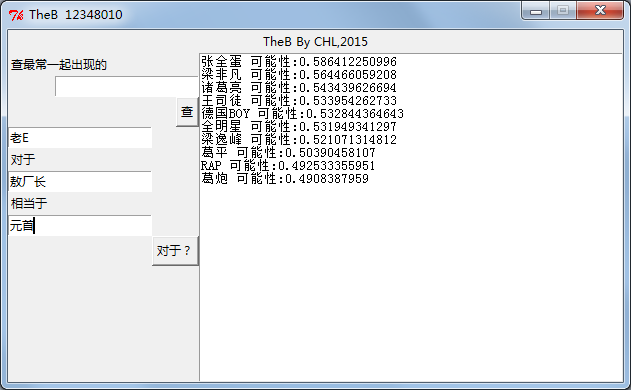
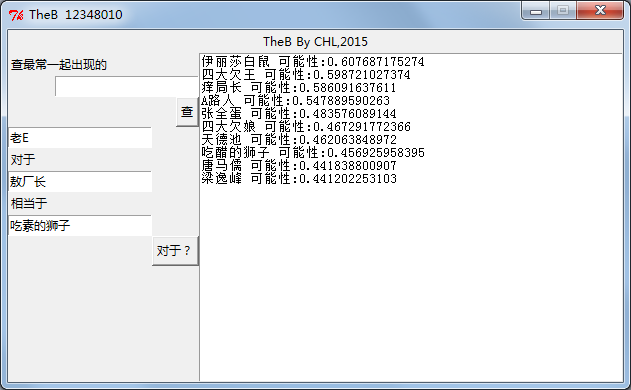
TheB就是这样了
我的PDF其实是用word生成的,为了在Word中加入高光,可以用以下这个网址
https://tohtml.com/python/
贴过来后将字体换成Consolas, 完美.