用Scrapy及Gensim对哔哩哔哩弹幕网的标签进行Word2Vec语义分析
本来是课程作业, 但也还是放出来吧.
Scrapy是一个爬虫,Gensim则是一个语义分析软件。Word2Vec是一个“深度学习”的,将一个个单词变为一个个向量的算法。
实际操作过程很简单, Scrapy抓Bilibili, Gensim对结果做Word2Vec分析, 然后用Tkinter写UI界面.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import codecs import scrapy from b.items import CHL import re class MySpider(scrapy.Spider): name = 'bili' allowed_domains = ['www.bilibili.com'] amy = ['http://www.bilibili.com/'] for i in range(7,2878725): amy.append("http://www.bilibili.com/video/av"+str(i)) start_urls = amy def parse(self, response): item = CHL(); try: item['tag'] = response.xpath('//meta[@name=\'keywords\']/@content').extract()[0] thestr = item['tag'].replace(',',' ') + '\n' with codecs.open('2878725', 'a', 'utf-8') as f: f.write(thestr) except IndexError: pass return item |
因为前几天上Bili发现编号只到2878725,所以就到2878725了。作业的版本是用CrawlSpider的,但其实B站视频编号连续,顺序爬就可以。顺序爬的速度比用爬虫爬快好多,而且占用资源也少。之前爬虫爬到结果大概不足100M,Linode那VPS就已经内存不足了,现在完整结果有316M。
由于有很多投稿失效或者是”只有会员知道的世界”,爬完后的结果里面,会有很多B站的默认Tag.为避免影响结果,要删去.
|
1 |
grep -v 'B站 弹幕 字幕 AMV MAD MTV ANIME 动漫 动漫音乐 游戏 游戏解说 ACG galgame 动画 番组 新番 初音 洛天依 vocaloid' 2878725 > 2878725fl |
2878725fl大约比2878725小一半…….
下一步之前还要把2878725fl改个名叫input
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/env python # -*- coding: utf-8 -*- import gensim, logging, codecs class MySentences(object): def __init__(self, dirname): self.dirname = dirname def __iter__(self): for line in codecs.open(self.dirname, 'r', 'utf-8'): yield line.split() logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = MySentences('input') model = gensim.models.Word2Vec(sentences, size=400, workers=24, min_count=3) model.save('w2v') model.init_sims(replace=True) model.save('w2v.trim') |
由于init_sims能极大减少内存占用,但却会令模型不能继续训练,所以就开启前后分别保存了一份,以备不时之需。这里的Size取了400,400就是向量的维度。
8192维的耗时
|
1 |
training on 19973050 raw words took 1883.2s, 10036 trained words/s |
400维的耗时
|
1 |
training on 19973050 raw words took 153.5s, 123083 trained words/s |
到准备重现UI时,发现32位的Python吃不了那么大的数据(1024维),去搞64bit的,所有包都要重新装….
http://www.lfd.uci.edu/~gohlke/pythonlibs/
上面这个网址有编译好的windows包可以直接用
举个栗子,下载numpy, 先把
numpy-1.9.2+mkl-cp27-none-win_amd64.whl下下来
然后
|
1 2 3 4 5 6 7 |
C:\Users\CHL\Downloads>pip install "numpy-1.9.2+mkl-cp27-none-win_amd64.whl" Unpacking c:\users\chl\downloads\numpy-1.9.2+mkl-cp27-none-win_amd64.whl Installing collected packages: numpy Successfully installed numpy Cleaning up... C:\Users\CHL\Downloads> |
搞定,然后就Scipy和Gensim,同理。
今天中大东校区IPv6废了,网速直线下降(我一直挂着v6跑)
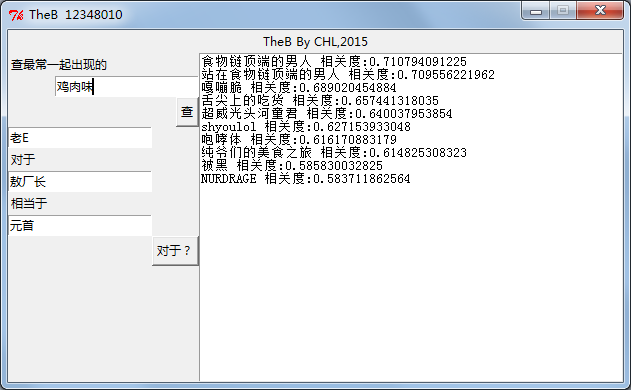
下面就是TheB跑出来的结果截图
相似查询概念很简单,就是找出向量距离近(相关度高)的结果
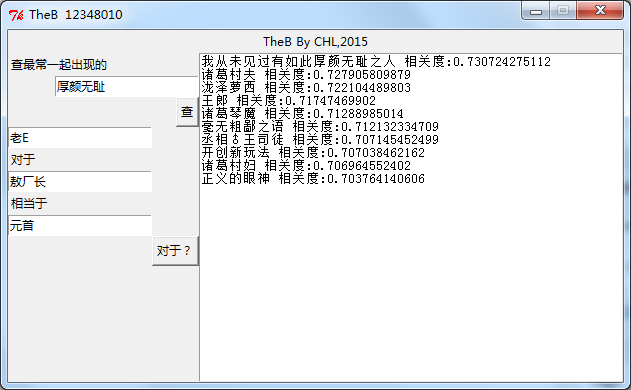
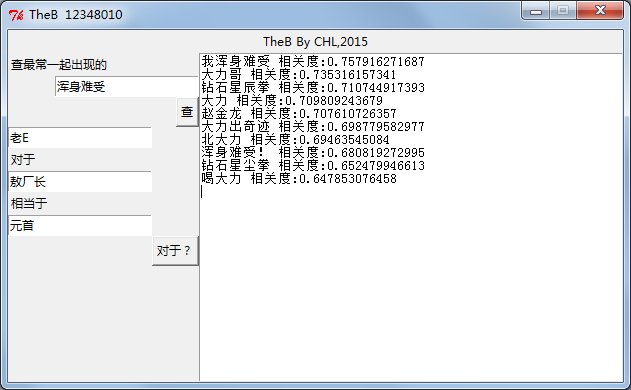
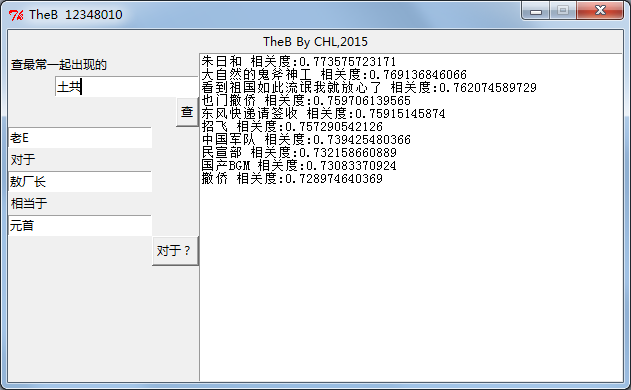
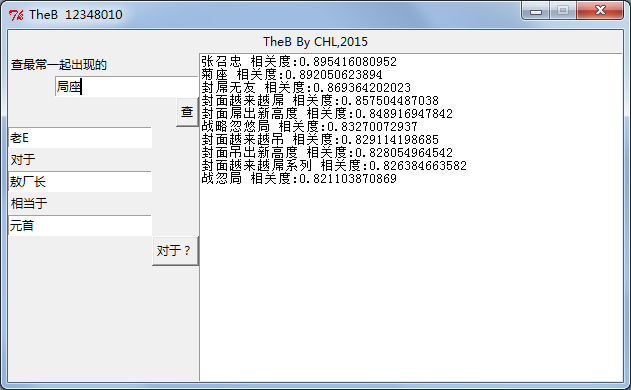
类比查询则比较有意思,一个简单的例子就是,queen对于girl相当于king对于boy。运算: boy=girl-queen+king。

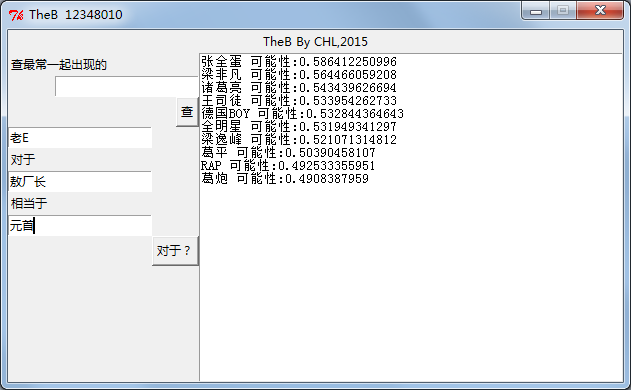
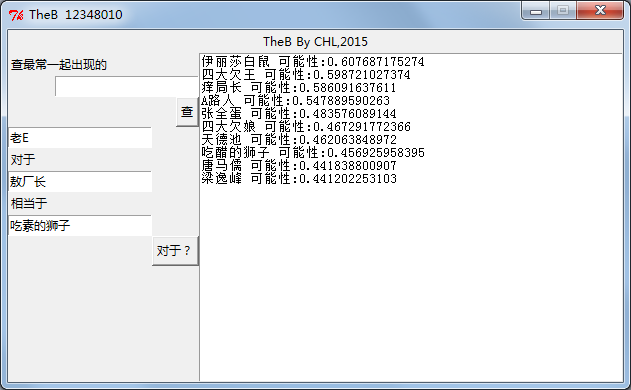
TheB就是这样了
我的PDF其实是用word生成的,为了在Word中加入高光,可以用以下这个网址
https://tohtml.com/python/
贴过来后将字体换成Consolas, 完美.
Nice!
Thank you!